はじめに
ようこそ、Agent-builder-kit のチュートリアルへ。
この mdBook は、agent-builder-kit で構築した AGENTS.md と docs/ を土台に作成しました。この過程を記録し、実際の成果物へどのように着手し、どう進めたかをチュートリアル形式で見てもらうことで、この mdBook の開発フローを追体験してもらうことが目的です。
制作および開発フローは、plan-manager が block を決め、task-planner が chunk と ticket に落とし、task-worker が実装し、必要なら reviewer が確認する流れになります。
このチュートリアルで扱うこと
agent-builder-kitを前提にした docs 駆動の進め方AGENTS.mdとdocs/exec-plans/を使った役割分担- mdBook を題材にした最小成果物の立ち上げと記録の残し方
- Obsidian の
.canvasと連携した開発フローの視覚化 - ハーネスエンジニアリングの一部である、タスクの細分化と境界分離の進め方
このチュートリアルで扱わないこと
- mdBook の全機能を網羅すること
- 一般的な AI 開発論だけを抽象的に語ること
- ハーネスエンジニアリングで語られる CI、カスタムリンター、厳密な境界分離を支えるレイヤードアーキテクチャを、この段階で詳細に実装し切ること
mdBook はここでは器です。器を作りながら、agent-builder-kit と、その土台にある docs 駆動開発 / ハーネスエンジニアリングの実際を一緒に確認していきます。
参考記事
- 「人間はコードを1行も書かない」という縛りで5ヶ月間プロダクトを作り続けた結果 ― ハーネスエンジニアリング | Qiita
- ハーネスエンジニアリング:エージェントファーストの世界における Codex の活用 | OpenAI
agent-builder-kit の導入
まずは agent-builder-kit を用意します。
新規プロジェクトを開始
Codex アプリで新規プロジェクトを立ち上げ、空のルートディレクトリを用意します。
Obsidian をまだ導入していない場合は、この段階で先に入れておきます。
公式サイトから Obsidian をインストールし、起動後に Open folder as vault を選んで、この project のルートディレクトリを Vault として開いてください。
Obsidian で project を開くと .obsidian/ が生成され、.canvas を使った開発フローの可視化も扱えるようになります。
agent-builder-kit を使った初期化では、次の 3 つがルート下に並ぶ状態から始めます。
.
├── .obsidian/
├── agent-builder-kit/
└── docs-builder.toml
.obsidian/: ノートアプリの Obsidian でこのプロジェクトを Vault として開くと生成されるファイルです。agent-builder-kitには.canvasと同期する Skill が同梱されており、開発フローを視覚化するコア機能でもあるため、Obsidian との連携を強くおすすめします。agent-builder-kit/:AGENTS.mdや構造化したdocs/を初期テンプレートとして展開するパッケージです。docs-builder.toml: builder が読み込む設定ファイルです。生成する docs 構成、planning layout、profile、add-on pack はこのファイルで決まります。agent-builder-kit/DOCS_BUILDER_TOMLを参考に、プロジェクトに合わせて編集してからルート下へ配置してください。
Obsidian の準備としては、ここで Vault として開ければ十分です。
.canvas の見方や、planning docs とどう同期されるかは後続の chapter で扱います。
パッケージの展開
Codex セッションを開始し、エージェントに agent-builder-kit を展開してもらいましょう。
例:
agent-builder-kit/PACKAGE_CONTENTS.mdと
agent-builder-kit/README.mdを読んでガイドに従ってください
展開が済むと、元のパッケージである agent-builder-kit を削除するか残すか尋ねられると思うので、不要であれば削除してください。
.
├── .agents/
├── .obsidian/
├── agent-builder-kit/
├── docs/
├── tools/
├── AGENTS.md
├── docs-builder.toml
└── README.md
準備はほぼ整いました!
ただしCodex アプリでは現在、セッションを開始した後に生成された Skill が即座に反映されないため、Codex アプリを再起動してください。
$ コマンドで次の Skill が候補に上がれば、準備は完了です。
Obsidian Canvas Sync
Plan Manager
Reviewer
Task Planner
Task Worker
これらのSkillを実際にどう使うかは後述のチャプターでお見せします。
展開した後のagent-builder-kitは削除しても、後で使いまわすためのテンプレートとして残しておいてもどちらでも構いません。
注意点
・すでにプロジェクトが進行中の場合
AGENTS.md および docs/ が存在するプロジェクトにおいては、docs-builder.toml を以下にすることで統合モードで展開できます。
[project]
mode = "migration"
ただし、すでに十分な .md が存在しドキュメントが膨大な場合は、完全な移行ができない恐れがあります。その場合は閉じたフォルダ下に展開したうえで現行 docs/ をバックアップし、移行タスクを細分化した上で進めてください。実験的な mode であるため、動作は保証できません。
・Claude環境下
未定義であるため保証できませんが、実体は Markdown と Python script 中心であるため、強依存はなく CLAUDE.md や tools/codex-skills/ に対する手動による最適化を行えば機能する見込みです。
・WSL環境でのObsidian
Windows 側の Obsidian から WSL 上のプロジェクトフォルダへは直接アクセスすることはできません。Linux 版 Obsidian をインストールし、WSLg で動作させてください。
Windows11 + WSL で Obsidian を快適に使うまでの試行錯誤 | Zenn
agent-builder-kit で開発を進める
このチャプターでは、agent-builder-kit を使った docs 駆動開発が、実際にはどの順で進んでいくのかをまとめます。
ここで扱うのは個別の機能追加ではなく、plan-manager から task-worker、そして本文化までをどうつないでいくかという全体の流れです。
このチャプターの読み方
最初に plan-manager で骨子を組む を読むと、project の要求をどう block に整理するかが見えてきます。
次に、
- task-planner で仕事を chunk と ticket に分ける
- task-worker で ticket を実行し、fact-report を返す
- 開発ログからチュートリアル本文を組み立てる
の順に追うと、計画の分解、実装、記録の再編集までを一続きの流れとして追えます。
最後の ハーネスエンジニアリングをさらに進める では、ここまでの流れを土台に、さらに先の設計観点を考えます。
このチャプターで扱うこと
このまとまりでは、主に次の論点を扱います。
- 要求整理を、どう block / chunk / ticket へ落としていくか
- role ごとに、どこまでを担当し、どこで次へ返すか
fact-reportや planning docs を、あとから本文へどう再構成するか.canvasを補助線としてどう見るか
つまりこのチャプターは、個別の作業内容そのものよりも、「開発フローをどのように運用すると破綻しにくいか」を読むための入口です。
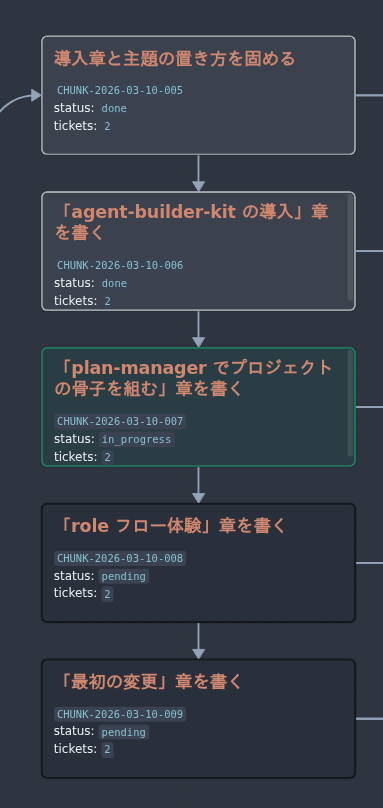
plan-manager で骨子を組む
セッションの開始
最初にやることは単純です。$ コマンドで、展開された Skill の中から plan-manager を選んで呼び出すだけです。
Codex アプリとの同期がうまくいっていれば候補に出るはずです。
では、この mdBook を作るにあたって最初に投げた言葉を見返してみましょう。
$plan-manager 環境を構築したところで、何もないんだけどどうすればいい?
こんな戯言でうまくいくとは思えませんが、実際これは覆すことのできない過去の出来事なので弁明の余地はありません。
しかし docs-builder.toml に何をやりたいかを書いていたのは幸運でした。
request = "何もない新規リポジトリから、agent-builder を使って mdBook のワークショップ記事サイトを作りたい。ワークショップ自体で plan-manager -> task-planner -> task-worker の流れも体験できるようにする。"
summary = "agent-builder の実運用を題材に、mdBook でワークショップ記事サイトを構築するプロジェクト"
これを足掛かりにして、`plan-manager` は以下のように返答しました。
plan-manager として、環境構築済み / mdBook 未着手の現状を planning docs に反映しました。
project-intake.md (line 11) に追加ヒアリングを記録し、
~中略~
docs/exec-plans/canvas/development-flow.canvas も再同期済みです。
次に BLK-001 を閉じるため、以下だけ決めたいです。推奨はすべて「最小で始める」です。
1.初回ゴールはローカル完結でよいですか。それとも公開導線まで含めますか。
2.章構成は 4 章前後で進めますか。
3.mdBook の立ち上げは手動で作りますか。それとも mdbook init 併用にしますか。
4.必須品質ゲートは mdbook build だけでよいですか。
このようなインタビューに答えて、大まかな骨子を組み立てていきます。
私は 1. については GitHub で公開するのをゴールと設定し、2. については「はい」、3. と 4. については「わからない」と答えました。そもそも mdbook を使うのが初めてだったからです。
plan-manager の役割
plan-manager は、要求整理と上流の計画更新を担当する role です。人間から受け取った要望をそのまま流すのではなく、確認済み事実、仮置き前提、未確定事項を分けながら、後続の role が迷わない骨組みへ整えます。
この段階で主に更新されるのは、次の docs です。
docs/exec-plans/project-intake.mddocs/exec-plans/discovery-brief.mddocs/exec-plans/plan-spec.mddocs/exec-plans/blocks/*.md
使い方はシンプルで、「何を作りたいか」と「いま分かっていること」を plan-manager に渡します。すると plan-manager は、block 単位の実行計画へ落とし込み、必要なら「何を先に決めるべきか」も返します。
たとえば今回の project では、mdBook を作ること自体よりも、agent-builder-kit を使った docs 駆動フローをどうワークショップ化するかが主題でした。そのため plan-manager は、公開ゴール、章構成、記録基盤、公開導線といった論点を block に分けて整理するところから始めています。
大事なのは、ここで細かい実装へ飛ばないことです。まず骨子を作ってから、次の task-planner が chunk と ticket へ分解する流れに入ることで、あとから見返しても追いやすい開発フローになります。
.canvas によるフローの視覚化
agent-builder-kit には、現在の docs の内容を汲み取って開発フローを視覚化する obsidian-canvas-sync が組み込まれています。
plan-manager や task-planner, task-worker がその仕事を終えると、自動的にスクリプトを呼び出し現在のタスクの進捗を拾い上げて.canvas ファイルを更新します。
Skillとして明示的に呼び出すこともできます。
Obsidianでdocs/exec-plans/canvas/development-flow.canvasを開き、進捗フローをリアルタイムに確認しながら開発業務を進めることができます。
このようなチャートがあれば、次に目指すべきブロックと何をやったかが明確になり、どこに新しい機能を追加するかも検討しやすくなるでしょう。
ハーネスエンジニアリングの特徴のひとつであるタスクの細分化は、エージェントの仕事をより高品質にしますが、その分その進捗を文章として追い、脳で処理する人間の負担は増えます。 Obsidianのような専用のViewerを使い、他のドキュメントに目を通す際にも有用です。
以下は、先述した plan-manager とのやり取りを踏まえて生成されたものです。
今はこのように単一のフローですが、次に task-planner を呼び出すことでどう発展するのかにも注目してください。

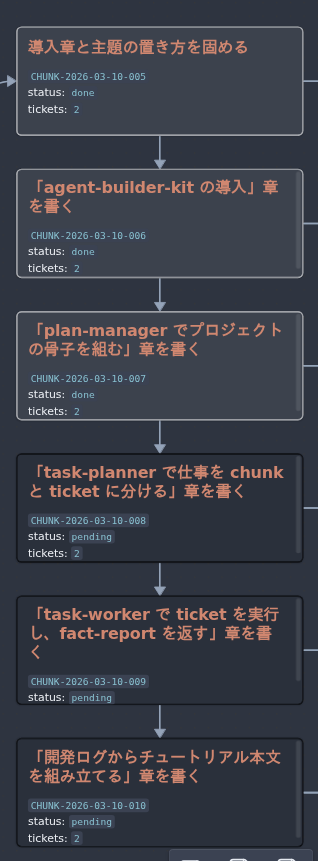
task-planner で仕事を chunk と ticket に分ける
plan-manager が project の骨子を block にまとめたら、次は task-planner の出番です。
ここでは、その block をそのまま眺めて終わるのではなく、実際に手を動かせる大きさまで分解していきます。
task-planner の役割
task-planner は、block を実行可能な単位へ分ける role です。
読むものは主に plan-spec.md と blocks/*.md、書き出すものは chunks/*.md と tickets/*.md です。
やっていることは単純で、次の二段階に分けて考えると分かりやすくなります。
- まず block を、意味のまとまりごとに
chunkへ分ける - そのあと各 chunk を、
task-workerが独立して進められるticketへ分ける
ここで重要なのは、最初から細かく切りすぎないことです。 逆に大きすぎる chunk や ticket を作ると、次に何をやるかが曖昧になり、role の境界もぼやけます。
task-planner の使い方
使い方は plan-manager と同じで、Codex アプリから Skill を呼び出します。
この project では、次のように依頼しました。
$task-planner ブロック2のチャンク化をおねがい。ちなみに私はmdbookのことはナニモワラカン
この一文だけでも、task-planner は block の目的と利用者の前提知識を読み取り、分解の粒度を調整します。
今回は mdbook 初学者向けに進める必要があったため、いきなり公開設定や装飾へ進まず、導入と確認を先に済ませる構成になりました。
block を chunk に分ける
実例として、BLK-002 では mdBook の初期セットアップを扱っていました。
これを task-planner は、次の 2 つの chunk に分けています。
CHUNK-001: mdBook 導入前提と雛形生成を固めるCHUNK-002: 初期章の配置とローカル検証を揃える
この分け方のポイントは、導入と検証を同じ箱に押し込めなかったことです。
先に入口と骨格生成を固め、そのあとで章の配置と build 確認へ進めることで、後続の task-worker が一本道で動きやすくなります。
chunk を ticket に分ける
chunk を切っただけでは、まだ task-worker は動きません。
そこで task-planner は、各 chunk をさらに ticket へ分けます。
CHUNK-001 では次の 2 ticket になりました。
TICKET-001: mdBook 導入前提と初回コマンドを整理するTICKET-002:mdbook initで最小骨格を作る
CHUNK-002 では次の 2 ticket になりました。
TICKET-003: 初期の章ファイルとSUMMARY.mdを整えるTICKET-004: build / serve の確認手順を残す
このように見ると、ticket は「1 回の実装依頼として無理なく完結する単位」になっていることが分かります。
役割ごとに言い換えるなら、chunk は人間が進め方を把握するためのまとまりで、ticket は task-worker が手を動かすための最小単位です。
chunk はあとから更新してよい
chunk は一度切ったら固定されるわけではありません。 むしろ、配下の ticket がすべて完了したあとこそ、いまの進捗と計画がまだ噛み合っているかを見直すタイミングになります。
たとえば、当初の chunk を最後まで進めてみてから、
- 現在の進捗と少しずれてきた
- この流れなら別の機能を足したくなった
- 次に進む前に、記録や検証のまとまりを追加したくなった
といったことが起こります。
そういうとき task-planner は、必要な更新が「いまの block の中に差し込む chunk なのか」、それとも「もっと上流で扱うべき新しい block なのか」を見ます。
block の目的に沿った追加であれば、現在の block に新しい chunk を差し込みます。
一方で、目的そのものが増えていたり、公開方針や記録方針のように上流判断が必要なら、task-planner は無理に追加せず、人間へ「これは block 単位で扱ったほうがよい」と返します。
このようにして、あとから必要になった chunk や block、ticket も、それぞれの境界と責務を見ながら適切な場所へ再配置されます。
以下は、chunk 更新前と更新後のイメージです。
更新前: 仮決めしていた章の構成が、タスク進行とともに噛み合わなくなった
更新後: task-planner に推敲を依頼し、軌道を修正
task-worker へどう渡すか
良い ticket には、少なくとも次の 3 つが入っています。
- 何を達成するかを示す
Goal - どこを触ってよいかを限定する
editable_paths - 完了をどう確かめるかを示す
Verification
これがあると、task-worker は scope を大きくはみ出さずに作業できます。
逆にここが曖昧だと、実装の迷いが増え、あとで review や記録も難しくなります。
task-planner は本文そのものを書かない代わりに、次の role が迷わないための枠組みを整える仕事をしています。
.canvas で分解後の姿を見る
chunk と ticket に分解されると、Obsidian の .canvas でも流れがかなり見やすくなります。
block だけだったときは「何をやるか」しか見えませんでしたが、chunk と ticket が入ると「次に誰が何をするか」が視覚的に追えるようになります。
この project では、task-planner が分解と差し込みを進めた結果として、開発フローが段階的に広がっていきました。
プロジェクト初期:
プロジェクト中盤:

ここまでできると、次は task-worker が各 ticket を順に実行し、fact-report と一緒に事実を返す段階へ進めます。
task-worker で ticket を実行し、fact-report を返す
task-planner が chunk と ticket を切ったら、次に実際に手を動かすのが task-worker です。
この role は、計画そのものを書き換えるのではなく、与えられた ticket の範囲だけを実装し、その結果を事実として返します。
task-worker の役割
task-worker が最初に見るのは、ticket の Goal, editable_paths, Verification です。
つまり「何を達成するか」「どこを触ってよいか」「何をもって完了とみなすか」を見てから作業に入ります。
ここで重要なのは、勝手に plan を拡張しないことです。 必要な変更が ticket の外へはみ出しそうなら、無理に進めず、ticket レベルで上流へ返します。
言い換えると task-worker は、実装担当であると同時に、境界を守る担当でもあります。
task-worker の使い方
呼び出し方はこれまでの role と同じで、Codex アプリから Skill を選ぶだけです。
この project でも、各 ticket を進めるたびに task-worker を呼び出し、対象 ticket の範囲だけを実行していきました。
たとえば TICKET-002 では、次のような仕事を受け持っています。
mdbook initを実行するbook.tomlとsrc/の生成物を確認する- 次の ticket が使いやすいよう、日本語の最小スタブへ整える
ここでは editable_paths が book.toml と src/ に限定されていたため、task-worker はその範囲だけを更新しています。
実装した結果をどう返すか
task-worker は、ファイルを変更して終わりではありません。
実装後は、ticket 本文の実施結果を埋め、さらに fact-report を返します。
fact-report には、少なくとも次のような事実が残ります。
- 何の ticket を実行したか
- どのファイルを変えたか
- どのコマンドを打ったか
- 何が起きたか
- 未解決事項があるか
これがあると、人間はあとから「何をしたのか」を会話ログに頼らず追えます。 同時に、次の role もその ticket の結果を一次記録として再利用できます。
今回の project でも、TICKET-002 の fact-report には、mdbook init --force --title "agent-builder-kit Tutorial" . を実行して最小骨格を作ったことや、book.toml, src/SUMMARY.md, src/agent-builder-kit-introduction.md が生成されたことが残っています。
reviewer が入るとき
reviewer は独立した章にはしませんが、task-worker の流れの中で重要な役目です。
コードや設定を実際に変更した ticket では、task-worker は実装後に reviewer へ handoff します。
この project では、TICKET-002 がその例です。
book.toml と src/ の実ファイルを更新しているため reviewer 対象になり、結果として no findings で通過しました。
一方、docs の更新と確認だけで終わる ticket では、毎回 reviewer を通す必要はありません。
たとえば TICKET-004 では、mdbook build と mdbook serve --open の確認結果を README と fact-report に残す作業が中心だったため、docs-only skip として扱われています。
この切り分けがあることで、review を必要な場所へ集中できます。
結果を上流へ返し、status を昇華させる
task-worker が結果を返したら、それで終わりではありません。
返ってきた ticket 本文、fact-report、review 結果を見て、次に task-planner が ticket を done へ上げます。
さらに、chunk 配下の ticket がすべて done になれば、task-planner は chunk close の材料をそろえます。
そのあと plan-manager が全体の進み方を見て、必要なら block の status も引き上げます。
つまり流れとしては、次のようになります。
task-workerが ticket を実行するfact-reportと review 結果を返すtask-plannerが ticket をdoneに昇格させる- 配下がそろえば chunk を閉じる
- さらに上流では
plan-managerが block の進捗を判断する
この流れがあることで、変更は単発で終わらず、開発フロー全体の進捗へ接続されます。
task-worker の返却物が大事なのは、そのまま上流の status 更新の根拠になるからです。
返ってくるものは変更だけではない
task-worker が返すのは、差分だけではありません。
実行したコマンド、確認結果、未解決事項、review の扱いまで含めて返すことで、あとから見た人が「どこまで終わっていて、何が残っているか」を判断しやすくなります。
だからこの role の本質は、単に実装することではなく、「実装を追跡可能な形で返すこと」にあります。
ここまでできると、task ごとの結果が一次記録として積み上がり、あとからチュートリアル本文へ再構成しやすくなります。
この project でも、task-worker が返した fact-report が、そのまま次の章づくりの根拠になっています。
開発ログからチュートリアル本文を組み立てる
この mdBook は、最初から完成した原稿があったわけではありません。 実際には、開発を進めながら残した planning docs と active logs を材料にして、あとから本文へ再構成しています。
この章では、その変換のしかたを見ます。 なお、この章そのものも最初から人間が立てたものではなく、AI エージェント側から「開発ログをどう本文へ変換したかも章にしたほうがよい」と提案し、それを採用する形で差し込みました。 そういう意味でも、この章はこの project の作り方をよく表しています。
先に、どの repo が何を持つかを固定する
本文化の手順に入る前に、repo の役割分担を先に決めておく必要があります。 これを曖昧にしたまま進めると、開発メモと公開原稿が混ざってしまい、あとから整理するコストが急に上がります。
この project では、次のように分けています。
- current repo
- planning docs、active logs、fact-report、運用設計の正本を持つ
- 試行錯誤や未確定事項も含めて残す
- tutorial repo
- current repo の記録をもとに、読者向けの章へ再構成した本文を持つ
- 説明の流れを優先し、内部向けの細部は必要な分だけ取り込む
この前提があるので、「まず current repo に一次記録を残し、その後に tutorial repo へ説明として編み直す」という順番を取りやすくなります。 以降の節では、その変換のしかたを具体的に見ていきます。
まず、どの記録が何のためにあるかを分ける
この project では、agent-builder-kit を土台にしつつ、記録を一か所へ雑に積むのではなく、役割ごとに分けています。
そのおかげで、あとから本文を書くときに「何が事実で、何が判断で、何が読者向けの説明候補か」を切り分けやすくなります。
たとえば、この project では次のように使い分けています。
project-intake,discovery-brief,plan-spec- 何を作るつもりだったか、最初に何を前提としていたかを見る
blocks,chunks,tickets- どの粒度で仕事を分け、どこで再計画したかを見る
fact-report- 実際に何をやったか、何が起きたかを見る
decision-log- どの判断を採用したかを見る
gotcha-log- どこで詰まり、どう回避したかを見る
command-log- 手順として再利用できるコマンドを見る
before-after- 変更前後を読者へ見せやすい粒度で拾う
article-source-map- 章ごとに、どの記録を根拠に使うかを整理する
raw log は current repo に残し、tutorial には抽象化して渡す
ここでいう raw log とは、開発中にそのまま残している一次記録のことです。 この project では、たとえば次のようなものが raw log にあたります。
- ticket 本文の実施結果
fact-report- 実行コマンド
- block / chunk / ticket の進捗メモ
- 差し込み要求や、その時点での未解決事項
これらは current repo に残します。 理由は単純で、raw log は再利用価値が高い一方、そのまま public な本文へ流すと情報量が多すぎるからです。
tutorial repo 側へ渡すときは、次の順で 1 段抽象化します。
- どの記録が事実の根拠になるかを選ぶ
- その中から読者に必要な部分だけを抜き出す
- 設計判断や学びとして読める順に並べ替える
つまり raw log は「公開しない」のではなく、「そのまま貼らない」と考えると分かりやすいです。 current repo に十分な一次記録があるからこそ、tutorial repo 側では説明の密度を調整しながら再構成できます。
role ごとに、どの段で何を残すかを分ける
この変換を安定して回すには、「誰がいつ何を残すか」をあらかじめ分けておく必要があります。 この project では、おおむね次のように考えています。
plan-manager- block の採否、順序変更、上流方針の確定を残す
- 後で「なぜその方針になったか」を説明したいときは
decision-logの材料になる
task-planner- chunk / ticket の分解や依存の組み替えを残す
- どの章でその再計画を扱うかは
article-source-mapに寄せていく
task-worker- 実装や docs 更新の事実を ticket 本文と
fact-reportに残す - その中で、読者価値のある詰まりどころや手順だけを
gotcha-logやcommand-logへ切り出す
- 実装や docs 更新の事実を ticket 本文と
つまり、まず各 role が本来の正本 docs を更新し、そのあとで記事化価値のある部分だけを補助 log に寄せます。 最初から全部を記事向けに書こうとしないことが大事です。
事実と解釈を混ぜない
本文を書くときにいちばん大事なのは、事実と解釈を最初から混ぜないことです。
たとえば fact-report に残っているのは、
- 実行したコマンド
- 変更したファイル
- 成功したこと
- 失敗したこと
といった一次記録です。
一方で、「なぜその判断をしたか」「読者に何を学んでほしいか」は、そのままでは本文になりません。
これは decision-log や article-source-map を使って、あとから意味づけしていきます。
つまり流れとしては、
- まず事実を残す
- 次に、その事実の中から使うものを選ぶ
- 最後に、読者向けの順番へ並べ替える
という順になります。
いきなり本文を書かず、source map を間に置く
この project では、本文を書く前に article-source-map.md を置いています。
これはかなり重要です。
source map があると、
- この章はどの記録を根拠にするか
- まだ何が足りないか
- 補助画像を使うなら何があるか
を、本文と切り離して考えられます。
この一段を挟むことで、「勢いでいい文章を書いたけれど、根拠がどこか分からない」という状態を避けやすくなります。
さらに言えば、source map は raw log と本文の間の「交通整理」でもあります。
fact-report、decision-log、gotcha-log、command-log、before-after を全部そのまま本文へ運ぶのではなく、
どの記録をどの節の根拠に使うかを、いったんここで落ち着いて決めます。
変換のタイミングは ticket 完了ではなく、章の節目で見る
raw log が増えてくると、毎回すぐに tutorial 側へ流したくなります。 ただ、この project ではそこも意図的に分けています。
- current repo では ticket 完了ごとに記録を残す
- tutorial repo では block close や milestone の節目で編成する
この差を設けることで、internal では細かい学びを落とさず残しつつ、public 側ではまとまった話として読める形に整えやすくなります。
もし ticket ごとにそのまま本文へ流してしまうと、読者にとっては途中経過が断片的に見えやすくなります。 そこで current repo 側に raw log を貯め、節目が来たときに source map や fact-report を見ながらまとめて編成する、という流れを取ります。
この project では、その節目を主に次のように見ています。
- current repo
- ticket 完了ごとに事実と補助ログを追加する
- tutorial repo
- block close、または milestone ごとに source map を見ながら章へ編成する
この 2 段構えにしておくと、開発の勢いを落とさずに記録を取りつつ、公開側では読みやすいまとまりを作れます。
記録はそのまま貼らず、読者向けに並べ替える
開発ログは時系列で積み上がりますが、チュートリアル本文は必ずしも時系列で読むのが最適とは限りません。
たとえば、この mdBook でも、
- 先に
agent-builder-kitの導入を書く - 次に
plan-managerとtask-plannerの流れを書く - そのあとで
task-workerや記録の使い方を書く
という順にしています。
実際の作業順と完全に一致していなくても、読者が理解しやすい順に並べ替えてよい、ということです。 ただしそのときも、根拠は source map と fact-report に戻れるようにしておきます。
この方法は他の成果物にも転用できる
この章のポイントは、mdBook を書くためだけの手法ではないことです。 成果物が別のアプリやライブラリであっても、
- 開発中に一次記録を残す
- active logs で判断と詰まりどころを整理する
- source map で本文との対応を作る
という流れはそのまま再利用できます。
つまり agent-builder-kit の価値は、単に plan を管理することではなく、「開発の記録そのものを、あとから説明可能な教材へ変換しやすくすること」にもあります。
少し大げさに言えば、開発しながら、そのまま次のチュートリアルの下書きも育てている、という感覚に近いです。
注釈:
decision-log,gotcha-log,command-log,before-after,article-source-mapは、agent-builder-kitに最初から同梱されていた機能ではありません。 開発の途中で、「今やっている作業もあとで本文に使いたい」とtask-plannerに伝えたところ、新しい chunk が差し込まれ、そのための記録機構がこの project の中へ追加されました。
ハーネスエンジニアリングをさらに進める
ここまでで、agent-builder-kit を使って、要求整理、chunk / ticket 分解、実装、記録、status 昇華までを一通り回せるようになりました。
ただし、これでハーネスエンジニアリングが完成したわけではありません。
むしろ今の kit は、使い始めやすさと汎用性を優先した、最小構成に近いものです。 ここから先は、project の規模や要求水準に応じて、さらに足場を強くしていく必要があります。
そもそもハーネスエンジニアリングとは何か
OpenAI の Harness Engineering で語られているのは、単に agent を賢くすることではありません。 agent が実運用の開発フローに入り込めるよう、評価、レビュー、実行境界、補助ツール、運用上のガードレールまで含めて整えることが主題です。
この見方に立つと、今の agent-builder-kit はすでに入口には立っています。
AGENTS.md、docs/exec-plans/、fact-report、.canvas によって、人間と agent が同じ source of truth を見ながら進める足場はできています。
一方で、スケールさせるにはまだ足りないものもあります。
今の kit ができていること
現時点でも、次の点はかなり強いです。
- role ごとの境界が docs と Skill で明示されている
- block / chunk / ticket / fact-report の流れが固定されている
.canvasで開発フローを視覚化できる- 作業結果が会話ログだけでなく docs に残る
この土台があるからこそ、あとから機能を拡張しても、どこへ組み込むかを議論しやすくなっています。
まだ足りないこと
今の agent-builder-kit は、まだ単一セッション寄りです。
複数の agent が同時並行で大きな project を回すには、次のような点が不足しています。
- 並列化可能な ticket を視覚的に見分ける仕組み
- 別セッションで同時に ticket を回すときの運用ルール
- CI/CD のような自動検証レイヤ
- より厳密な境界分離を支える設計支援
このあたりは、project が大きくなるほど重要になります。
マルチエージェント化するなら
今の流れをそのまま拡張するなら、まずは chunk と ticket の並列化条件をもっと明示するのが自然です。
たとえば、
- 並列実行してよい ticket を
.canvas上で色分けする - 競合しない
editable_pathsを持つ ticket だけを別セッションへ渡す depends_onがない ticket を同時に回す
といった運用が考えられます。
このとき大事なのは、「並列で回せそうだから回す」のではなく、「境界が見えていて衝突しないから並列で回せる」状態にすることです。
その意味で、将来的には .canvas の managed lane に、並列実行可否や担当色を持たせる拡張もありえます。
CI/CD は入れるべきか
結論から言うと、実運用を強めるなら入れるべきです。 今の kit は、ローカル build や reviewer handoff までは扱えますが、継続的な自動検証までは標準で持っていません。
ただし、CI/CD は project 依存がかなり強い領域です。 どのテストを必須にするか、どのブランチ戦略を取るか、どこで deploy するかは、成果物によって大きく変わります。
そのため agent-builder-kit では、汎用性を優先して CI/CD を標準同梱していません。
必要なら project ごとに add-on pack や専用 Skill として差し込む、という考え方のほうが自然です。
同じ文脈で、リンターも標準では抱えていません。
たとえば Rust なら Clippy を導入することで、コード品質をかなり簡単に底上げできます。
ただし、どの lint を必須にするか、どこまで厳しくするかも project 依存が強いため、これも agent-builder-kit の標準範囲には入れていません。
必要なら CI/CD や review ルールと合わせて、その project 用に差し込むべきものです。
レイヤードアーキテクチャや境界分離を強めるなら
同じことはレイヤードアーキテクチャにも言えます。 どこで domain を切るか、どのフォルダ構成にするか、どこまで interface を分けるかは、project ごとの差が大きいからです。
これも汎用テンプレートに固定で埋め込むより、必要に応じて拡張できるほうがよいでしょう。 たとえば、次のような Skill を追加する余地があります。
architecture-creatorfolder-structure-designerboundary-reviewer
こうした Skill があれば、task-planner や task-worker とは別に、「構造をどう切るか」だけを専門に扱えます。
それは、より厳密な境界分離を求める project で特に効いてきます。
どこまで kit に入れるべきか
ここで難しいのは、全部入りにしすぎると kit が重くなり、逆にどの project にも合わなくなることです。
だから今の agent-builder-kit は、意図的に最小寄りにしています。
つまり方針としてはこうです。
- 共通で効くものは最初から入れる
- project 依存が強いものは add-on や Skill で差し込む
- 使いながら必要な役割をあとから増やす
この方針なら、汎用性を保ちながら、実運用に合わせて強くできます。
今後の拡張候補
今の時点で、次の拡張はかなり筋がいい候補です。
- 並列化可能 ticket の可視化
- 別セッションでの multi-agent 実行ルール
- CI/CD 用 add-on pack
- lint / static analysis 用 add-on pack
- アーキテクチャ設計専用 Skill
- 境界逸脱を重点的に見る reviewer 拡張
この章で言いたいのは、「今の kit は不完全だ」ということではありません。
むしろ、今の agent-builder-kit は展開スクリプトと .canvas 同期の Skill を除けば、ほとんどが .md の docs でできています。
だからこそ、この kit を土台にしながら、自分の project に合わせて役割や運用を拡張しやすいのです。
conductor を加えて開発フローを自動化する
この章で扱うのは、「新しい agent を 1 つ足した」という話ではありません。
人間が毎回 role を選び直さなくても進められる入口をどう作るか、そしてその入口をどこまで安全に広げるか、という話です。
もともと agent-builder-kit には block、chunk、ticket を回す土台がありました。
ただ実運用では、次のような細かな判断が残ります。
- 次にどの role を呼ぶか
- 人間の差し込み要求をどこで拾うか
- reviewer をどこまで same-turn で通すか
- 公開用の mdBook 本文へどこまで引き上げるか
そこで current repo では、薄い制御層として conductor を足しつつ、
- 段階実行(bounded multi-step)
LEVEL=MID|HIGH step=<num>- reviewer pass-through
- package backport
までを段階的に固めました。この章は、その流れを「まずどう使うか」が見える形で読み直すための入口です。
この章の読み方
まずは なぜ conductor が必要だったのか で、「なぜ conductor を足したのか」「current repo と package と tutorial repo をどう役割分担したのか」を掴むのが早道です。
そのうえで、次の順に読むと自然につながります。
- read-only な conductor から始める
- bounded multi-step と run level を加える
- conductor の使い方と検証結果
- conductor 拡張の到達点
前半ほど「なぜ必要だったか」、後半ほど「どう使い、何が確認できたか」に寄ります。
この章全体で持ち帰ってほしいこと
この章全体で見てほしいのは、細かな実装一覧ではなく次の流れです。
- なぜ
agent-builder-kitに追加の自動化が必要だったのか conductorを read-only advisor から段階実行の入口へどう広げたのか- それを日常運用でどう使い、どこに安全境界を置いたのか
親章であるこのページは、各中チャプターをつなぐハブです。
どこから読めばよいか迷ったら、このページへ戻ると全体の流れを追い直せます。
なぜ conductor が必要だったのか
この project の出発点は、「agent-builder-kit はすでに使えるが、実際に回すと毎回細かい判断が残る」という感触でした。
plan を block、chunk、ticket に分けるところまでは整っていても、その先で人間が何度も「次は誰を呼ぶべきか」「追加要求をどこで差し込むべきか」「この結果を package や tutorial にどう戻すべきか」を考え直す場面が残っていたからです。
最初から目指していたのは、何でも自動化することではありませんでした。人間が裁定すべきところは残したまま、繰り返し出てくる role routing を薄く整えることが目的でした。そこから conductor を read-only advisor として足し、さらに bounded multi-step、LEVEL=MID|HIGH step=<num>、reviewer pass-through へ広げていったのが今回の流れです。
なぜ追加の自動化が必要だったのか
agent-builder-kit の基本的な流れは、すでにかなり整理されています。
plan-manager が骨子を作り、task-planner が chunk と ticket に分解し、task-worker と reviewer が実行と確認を進める、という流れです。
ただ、実際にしばらく運用すると、次のような摩擦が見えてきます。
- 複数の ticket をまたぐと、次にどの role を呼ぶか毎回人間が思い出す必要がある
- shell や bash loop で半自動化しようとすると、人間の差し込み要求をどこで拾うかが曖昧になる
- 開発ログを public な tutorial へ流したいが、internal な planning docs と公開記事の境界を保つ必要がある
ここで見えていたのは、役割の不足ではなく、役割同士のあいだを読む薄い制御層の不足です。
すでに plan-manager も task-planner も task-worker もいるのに、role の切り替えや差し込み要求の扱いでは毎回人間が流れをつなぎ直していました。
つまり足りないのは、実装能力ではなく「流れを読む薄い制御層」でした。
この project では、その制御層を conductor として設計しています。
この project は何をやっているのか
実際には、この project は 1 つの機能追加だけをやっていたわけではありません。 途中で要求が足されるたびに、次の 3 本を並行して整理する必要が出ました。
conductorという read-only な制御層を追加する- queue を使って loop 実行中の人間要求を安全境界で差し込めるようにする
conductor-onlyentry から same-block bounded multi-step、さらにHIGHの narrow cross-block handoff まで広げる- reviewer pass-through と package backport を既存 role 契約の上で追加する
- 開発中の判断や結果を mdBook 側へ流せるよう、記録と公開の導線を整える
ここでいう conductor は、計画そのものを書き換える役ではありません。
むしろ最初に決めたのは、「何でもできる orchestration agent にしない」ことでした。
plan-manager, task-planner, task-worker, reviewer の既存の役割分担を壊さずに、現在の docs を読んで「次は誰が動くべきか」を案内する役として置いています。
conductor は何をするのか
初期版の conductor は、docs を正本として読んだうえで、次にどの role へ戻すべきかを返すだけの軽い役割に留めます。その後、設計を壊さない範囲で bounded multi-step の入口へ広げましたが、今でも status 意味変更や最終裁定までは持ちません。
やることは主に次の 3 つです。
plan-spec,blocks,chunks,tickets,operator requestsを読み、現在の状態を集約する- pending の operator request があるかを確認する
- 次に
task-plannerへ戻すべきか、通常どおり次 ticket を進められるかを案内する LEVEL=MIDでは同一 block 内だけ、LEVEL=HIGHでは block-only 状態から narrow handoff を許す- bounded run の中で
task-worker -> reviewer -> task-plannerの pass-through を通す
加えて、promotion_candidates や sync_warnings を返して、機械的に見つけられる同期漏れを可視化します。
ただし、ここで大事なのは conductor が read-only だという点です。
status の更新や最終裁定は引き続き task-planner / plan-manager が持ちます。
この境界は途中で何度も再確認されました。
warning が出たときにもっと強く差し戻した方がよいのではないか、.canvas sync まで conductor に集約した方が自然ではないか、という話も出ましたが、この段階では「まずは read-only でどこまで役に立つかを見る」方針に留めています。
人間要求をどこで差し込むのか
今回の拡張で強く効いた要求の 1 つが、「bash で loop を回している最中に、今の ticket が終わったら一言差し込みたい」というものでした。 これは単なる UI の話ではなく、安全境界をどこに置くかという設計の話でもあります。
この project では、実行中の ticket を無理に止めるのではなく、安全境界を after_current_ticket に固定します。
つまり、今の ticket が終わったあとにだけ pending request を拾い、次の流れを再判定する形です。
そのために、docs/exec-plans/operator-requests/REQ-*.md という request file を追加していきます。人間は template から request を作るだけでよく、conductor はそれを読んで「まず task-planner へ返す」「必要なら plan-manager へ上げる」と案内する設計です。
この方式の利点は、すべてを docs 正本の世界に留められることです。 メモリ上の一時イベントではなく、あとから見返せる記録として残るため、開発ログとしても扱いやすくなります。
current repo と tutorial repo の役割分担
この project では repo を 2 つに分けていますが、同じ内容を二重管理したいわけではありません。 むしろ、途中で「何を generic package に戻し、何をこの repo 固有に残すか」を整理した結果、この分担がはっきりしました。
役割は次のように分かれます。
- current repo
- 進行中の計画、ticket、fact-report、設計メモを保持する
- まだ公開向けに整っていない試行錯誤も残す
conductor、operator request、run level、reviewer pass-through のような運用設計の正本を持つ
- package repo (
agent-builder-kit)- generic runtime、shared role-skill 契約、最小限の docs を受ける upstream として扱う
- current repo 固有の validation 実測や temp fixture 名は持ち込まない
- tutorial repo
- current repo で残した記録を、読者向けの説明順に並べ替えて公開する
- 内部運用の細かい文脈をそのまま出すのではなく、理解に必要な部分だけを抜き出す
- mdBook として読みやすい章構成を保つ
つまり、current repo は開発現場の正本であり、tutorial repo は説明用の再編集物です。 この線引きを先に決めておくことで、「とりあえず両方に同じことを書く」という非効率を避けやすくなります。
このあと何を読むか
ここから先は、前段のガイドを踏まえたうえで次の流れで読むのが自然です。
開発のメインパートconductor-onlyentry、bounded multi-step、MID/HIGH、reviewer pass-through、package backport の中核部分
検証・使い方・統括- hard stop、queue、Codex Action、
[$conductor] LEVEL=MID|HIGH step=<num>、代表シナリオの観測結果、締めの整理
- hard stop、queue、Codex Action、
この章は、読者が「この拡張は何のためにあり、どの要求追加が設計変更を呼び、どこまでを最小実装として扱ったのか」を先に掴むための入口です。
read-only な conductor から始める
このチャプターで先に掴んでほしいのは、「conductor に何をやらせないまま始めたか」です。
自分でも agent-builder-kit を拡張したいなら、最初から強い自動化を目指すより、既存の role 契約を壊さない薄い入口を先に作る方が安全です。
ここでの要点は 3 つです。
conductorは最初から何でも実行する agent にはしなかった- 入口は 3 本の薄い script に分けた
- 後から差し込みたい要求は、途中割り込みではなくキューで扱うようにした
最初に決めたのは「全部やらせない」ことだった
今回の拡張で最初に大きかった判断は、conductor を何でもできる agent にしないことでした。
もしここで docs 更新や status 変更まで持たせると、plan-manager、task-planner、task-worker が持っていた責務境界が一気に曖昧になります。
そこで初期版では、conductor を read-only に留める方針を先に固めました。
- docs を読む
- current state を集約する
- 次に呼ぶ role を案内する
まずはここまでです。
この判断が入ったことで、以後の実装は「何を足すか」より先に「これは既存 role の責務を奪わないか」で考えられるようになりました。
最小構成は 3 本の入口だった
最初に揃えたのは、厚い orchestration runtime ではなく、役割の違う 3 本の入口でした。
flow_conductor.pyrun_conductor.shadd_operator_request.sh
それぞれの役割は明快です。
flow_conductor.py- 状態を読み、次の role や hard stop を返す正本
run_conductor.sh- 人間や Action から叩きやすいラッパー
add_operator_request.sh- 後から差し込みたい要求をキューへ積む helper
この分け方の利点は、「どこが正本で、どこが人間向けの入口か」が崩れにくいことでした。 自分で拡張するときも、まずはこの 3 分割に近い構成から始めると、あとで責務が混線しにくくなります。
名前も設計の一部だった
この段階では rename も設計判断でした。
flow-orchestrator のような名前だと、何でも勝手に進める主体を連想しやすくなります。
そこで conductor という呼び名に寄せました。
意味としては「全部を実行する主体」ではなく、「今の状態を読んで次の動きを整える主体」に近いからです。
名前を変えるだけでなく、実際の役割もその名前に合わせました。
だからこの時点の conductor は、まだ「強い自動化」ではなく「薄い入口」です。
追加要求は途中割り込みではなくキューにした
運用を考えると、必ず出てくるのが「この ticket が終わったら、次にこれもやってほしい」という要求です。 ここで実行中 ticket の途中割り込みを既定にすると、一気に壊れやすくなります。
そこで、追加要求は REQ-*.md をキューとして積み、after_current_ticket の安全境界でだけ拾う形にしました。
流れは次のとおりです。
- 人間が request file を作る
- current ticket が終わる
conductorが pending request を検知する- hard stop として upstream role へ返す
task-plannerが chunk / ticket 追加で閉じるかを判断する
この方式の良いところは、差し込み要求があとから見返せる docs になることです。 単なる割り込み制御ではなく、「何を追加したかったか」が記録として残ります。
warning は「裁定」ではなく「見える化」に留めた
read-only 期で早く効いたのは、派手な自動化ではなく status 同期漏れの検知でした。
そこで promotion_candidates、sync_warnings、table_frontmatter_mismatches を返すようにしました。
ここでの狙いは、「機械的に見つけられるズレを見えるようにすること」です。
- 配下 ticket が終わっているのに chunk が
in_progressのまま - table と frontmatter がずれている
- close-ready だが source docs sync が残っている
ただし、直す主体は conductor ではありません。
実際に同期したり昇格したりするのは task-planner と plan-manager に残しました。
つまり conductor は、warning を見せることはできるが、そこで意味判断まで持つ主体ではないということです。
人間向け summary と JSON を分けた理由
flow_conductor.py の正本出力を JSON に置いたのは、script や Action から壊さず扱えるようにするためです。
一方で、人間が毎回 JSON を読むのはつらいので、--human では summary を出すようにしました。
この分け方のおかげで、
- 機械は JSON を読む
- 人間は summary を読む
という自然な役割分担ができます。
自分で似た仕組みを足すなら、「機械向け正本」と「人間向けの読みやすい出力」は最初から分けておく方が安全です。
ラッパーを薄くしたのも理由がある
run_conductor.sh を厚くしすぎなかったのも、同じ考え方です。
ここで解釈ロジックまで抱え込むと、shell loop、Action、将来の別入口で挙動がずれやすくなります。
そのためラッパーの責務は、基本的に次の 2 つへ絞りました。
flow_conductor.pyを呼ぶ- hard stop 時に人間向けの note と exit code を返す
この最小さがあったので、あとから MID/HIGH や close-ready handoff を足しても、core と入口を分けて考えやすいまま保てました。
この段階で自分が真似するなら
もし自分でも agent-builder-kit を拡張するなら、この段階では次の指示から始めるのが自然です。
conductorは read-only に留める- docs 更新や status 変更は既存 role に残す
- 入口は Python 正本、ラッパー、追加要求 helper の 3 本に分ける
- 追加要求は途中割り込みではなくキューで扱う
- warning は見える化に留め、裁定は上流 role に残す
この段階で無理に「全部自動で進めたい」へ振らなかったことが、後段の拡張を安全にしました。
次のチャプターでは、この薄い入口を保ったまま、どこまで実運用向けに広げたかを扱います。
bounded multi-step と run level を加える
ここから先で扱うのは、「conductor が実際にどこまで進められる入口になったか」です。
読者として先に見てほしいのは、内部実装の列挙ではなく、次の 4 点です。
- どこまで自動で進み、どこで止まるのか
LEVEL=MIDとLEVEL=HIGHをどう使い分けるのか- reviewer をどこまで same-turn で通せるのか
- package 側へ何を戻し、何を戻さなかったのか
まず広げたのは「段階実行」だった
conductor-only entry が成立したあと、次に必要になったのは「人間が毎回 task-worker と task-planner を呼び直さなくても、同じ block の中ではある程度先へ進めたい」という要求でした。
ここで採ったのは、無制限 auto ではなく、段階実行(bounded multi-step)です。
最初に固めた contract は次のとおりでした。
- 既定は
LEVEL=MID MIDでは同一 active block の中を進める- 既定の上限は
5step - hard stop、
plan_manager境界、reviewer blocking、step 上限で止まる
重要なのは、「進める」ことより「どこで止まるか」を先に固定した点です。 この順序を守ったことで、bounded multi-step を足しても既存 role の裁定権は壊れませんでした。
close-ready handoff を足して、見える挙動にした
段階実行を入れた直後は、docs 上では正しくても、人間から見ると task-worker 側に張り付いて見える gap が残りました。
そこで追加したのが close-ready handoff です。
ここでやったのは、promotion_candidates 全体を強い route 変更理由にすることではありません。
active frontier 自体が close-ready で、task-planner に source docs sync をさせないと次へ進めないときだけ、same-turn で task_planner に返す narrow policy を足しました。
この修正で、task_worker -> task_planner -> task_worker の visible handoff が成立しました。
人間から見ても「段階実行が本当に same-turn でつながっている」と分かるようになったのが、この段階の大きい改善です。
LEVEL=MID|HIGH step=<num> はどう使うか
次に出た要求は、「5 step 固定だと block の規模によって短い」というものでした。 ただし、ここでも上限撤廃はしませんでした。
整理した run level は次のとおりです。
LEVEL=MID- 1 block を終わらせる側の既定
- active block しか無く、次に必要なのが chunk / ticket 生成なら
task_plannerへの 1 段返送も含む
LEVEL=HIGH- その
MIDを含んだまま、block close-ready ではplan_manager返送を優先する上位 level
- その
step=<num>- 既定
5を上書きする bounded override
- 既定
ここでの step=20 は「無制限にする」ではなく、「今回の block は実質最後まで進めたいので cap を大きめにする」という意味です。
HIGH でも何でも自動で進むわけではない
HIGH を入れると、block 間を何でも進めてよいと誤解しやすくなります。
実際にはそうしていません。
HIGH の cross-block handoff は、child chunk 未生成の block-only 状態に限定しました。
既に child chunk がある block-only 状態では、上流裁定が残っている可能性が高いので plan_manager を優先します。
つまり HIGH は「強い自動化」ではなく、
- 1 block をかなり先まで進める
- そのうえで block close-ready では
plan_manager返送までを受ける
という bounded な上位設定です。
人間向け override は準正規形に寄せた
ここは使い勝手に直結する部分でした。
自然文の完全自由入力より、LEVEL=MID|HIGH step=<num> の準正規形を強く求める方が安全です。
skill 側はこれを --level と --max-steps に正規化して runtime へ渡します。
この折衷のおかげで、使い方はシンプルに保ちつつ、解釈の揺れを減らせました。
reviewer は no-findings path だけ same-turn で通した
code ticket のたびに reviewer 境界で必ず止まると、段階実行の価値が薄くなります。 一方で、重大 finding を素通りさせるわけにはいきません。
そこで reviewer pass-through は 2 段で整理しました。
- no-findings path では
task-worker -> reviewer -> task-planner - blocking findings があるときだけ return boundary
この形にしたことで、reviewer を人間入口の direct target に増やさず、それでも same-turn bounded run を無駄に止めずに済むようになりました。
package backport では current repo 固有ログを持ち込まなかった
current repo で bounded multi-step、MID/HIGH、reviewer pass-through が固まったあと、generic な差分だけを package へ戻しました。
ここで重要だったのは、current repo 固有の validation 実測や temp fixture 名、fact-report をそのまま package へ混ぜないことでした。
戻したのは主に次の帯です。
- runtime
- skill
- shared contract docs
逆に current repo 固有の観測は local validation として残し、package には generic contract だけを戻しました。 この切り分けをしないと、後から package を読む人にとって「何が一般化された仕様で、何がこの repo 固有の記録か」が分かりにくくなります。
この段階でまだ見送ったもの
ここで大事なのは、実装したものだけではありません。
何をまだ決めないまま残したかも同じくらい重要です。
たとえば、
- warning 時に route をどこまで変えるか
.canvassync を将来的にどこへ集約するか- package bootstrap 前の default path をどう整えるか
といった論点は、この段階では「解決済みの設計」としては書かないことにしました。 最小実装として確認できた事実を越えるからです。
ここまでで自分が読むべきポイント
このチャプターを読み終えたら、少なくとも次の理解が残れば十分です。
conductorは bounded に数 step 進める入口になった- 既定は
MID / 5 HIGH / 20は強めだが bounded な上位設定- reviewer は no-findings path だけ same-turn で通す
- package へは generic contract だけを戻す
次のチャプターでは、これを実際に使うときに何が便利で、どこで hard stop やキューを使うかを扱います。
conductor の使い方と検証結果
このチャプターで最初に知ってほしいのは、「いま自分がどう使えばよいか」です。
検証結果はその裏付けとして扱い、まずは daily use の形から説明します。
まず覚える使い方
日常運用では、入口は conductor だけに寄せられます。
人間が覚える形は次の 2 つで十分です。
[$conductor] LEVEL=MID step=5
[$conductor] LEVEL=HIGH step=20
読み方はシンプルです。
MID / 5- 1 block を終わらせる側の既定
HIGH / 20- より強めに進めたいときの上位設定
- ただし無制限 auto ではない
迷ったらまずは MID / 5 で始めます。
block をかなり先まで進めたいときだけ HIGH / 20 を使えば十分です。
hard stop は失敗表示ではなく安全装置
ここで重要なのは、hard stop を「壊れた表示」と読まないことです。
hard stop は、そこで人間へ返すべきだと分かった境界を示しています。
代表例は次の 3 系統です。
- pending operator request
- loop retry detected
- bundled confirmations detected
これらが出たときは、自動続行より人間判断を優先します。
むしろ hard stop が見えることで、「どこまで自動で進め、どこで止めるか」が読みやすくなります。
キューは「あとで拾う要求置き場」として使う
途中で追加したい要望が出たら、キューへ積みます。
ここでの考え方は「今すぐ割り込ませる」ではなく、「次の安全境界で確実に拾う」です。
たとえば次のように request を追加します。
bash scripts/add_operator_request.sh --summary "追加したい要望"
流れは次のとおりです。
- 人間が request をキューへ積む
- current ticket が終わる
conductorが pending request を検知する- hard stop として upstream role へ返す
この読み方を守ると、「後から一言差し込みたい」が unsafe な途中割り込みになりません。
Codex Action を使うとワンボタン化できる
毎回手でコマンドを書くのが面倒なら、Codex アプリの Action を使います。
手順は次のとおりです。
設定環境- プロジェクト名横の
+ アクションを追加bashを登録
たとえば bash scripts/run_conductor.sh --human を Action にしておけば、UI 上部タブからワンボタンで conductor 入口を呼べます。
ここで大事なのは、Action は main contract ではなく人間向けの近道だということです。
正本はあくまで conductor skill と run_conductor.sh です。
実際の検証で何を見たか
この段階で見たかったのは、未来の完全自動化ではありませんでした。
まず確認したかったのは、「docs 駆動の flow を壊さずに conductor を差し込めるか」です。
観点は大きく 5 つでした。
- 通常実行で current state と next role が自然に読めるか
- pending operator request があるときに、安全境界でちゃんと差し戻せるか
- 段階実行(bounded multi-step)で
task_worker、task_planner、plan_managerの返送境界が読めるか - reviewer pass-through を no-findings path では通し、blocking finding では止められるか
- status 同期漏れのようなズレを warning として拾えるか
つまり「便利そうか」ではなく、「実際の flow の中で役割を持てるか」を見ました。
通常実行で分かったこと
通常実行では、run_conductor.sh --human で summary が読め、JSON 正本も壊れず返ることを確かめました。
ここで価値があったのは、派手な自動化より「いま何が起きているか」が読みやすくなることでした。
next_role、pending request 数、完了候補、同期警告がまとまって見えるだけでも、人間が頭の中で role の流れをつなぎ直す負荷はかなり下がります。
pending request で分かったこと
queue を使った差し込み要求も、想定どおり機能しました。
- request を追加する
- current ticket が終わる
conductorが pending request を検知するtask_plannerへ返る
この流れが確認できたことで、queue は単なる補助 script ではなく、運用上の安全装置として成立していると分かりました。
段階実行で分かったこと
段階実行を入れたあとに確認したかったのは、same-turn で本当に handoff が見えるかでした。
そこで close-ready handoff を足したあと、task_worker -> task_planner -> task_worker の visible handoff が current repo で観測できるようになりました。
つまり bounded multi-step は「何となく先へ進む」ではなく、
- どこまで同じ turn で進むか
- どの境界で返るか
が読める形へ進んだわけです。
MID/HIGH と step の override で分かったこと
override を入れたあとに確認したのは次の 2 点です。
- default の
MID / 5が日常運用の既定として十分使える HIGH / 20にしても hard stop や reviewer blocking の境界は越えない
reviewer pass-through で分かったこと
reviewer pass-through は、no-findings path では流れを止めず、blocking finding ではきちんと境界になることが確認できました。 これにより、「reviewer を毎回人間入口の direct target にしなくても、必要なところだけ bounded run 内へ通せる」と分かりました。
warning で分かったこと
status 同期漏れや table / frontmatter mismatch のような warning も temp copy で検証しました。 ここで分かったのは 2 つです。
- warning の検知自体は効く
- ただし warning だけで route が強く切り替わるわけではない
つまり conductor は warning を見えるようにはするが、そこで何でも裁定する主体ではまだありません。
この限界も、実際の観測結果として確認できました。
次の中チャプターでは、ここまでで何が実用になり、何を residual として残したかを短く整理します。
conductor 拡張の到達点
この中チャプターの役割は、technical 事実を増やすことではなく、「ここまでで何が実用になったか」を短く整理することです。
結論から言えば、conductor は docs 駆動フローの外側に置く薄い制御層として始まり、いまは段階実行と MID/HIGH override を持つ実運用入口として十分使えるところまで来ています。
実用面で効いたのは、特に次の 4 点でした。
- 通常実行で current state を読みやすく返す
- pending request を安全境界で拾って差し戻す
- bounded run の返送境界と warning を visible にする
- reviewer pass-through を no-findings path では通し、blocking path では止める
一方で、まだ後続判断に残している論点もあります。
- warning 時に route をどこまで変えるか
- package bootstrap 前の default path をどう整えるか
- mirror や public 導線をどう保守するか
つまり今の conductor は、何でも自動で進める agent ではありません。
docs を読み、bounded に flow を整え、どこで人間へ返すべきかを分かりやすくする runtime advisor と読むのがいちばん正確です。
この状態まで来たことで、「次にどこを広げるか」も以前よりずっと判断しやすくなりました。
おわりに
このチュートリアルでは、agent-builder-kit を使って、何もないところから mdBook を立ち上げ、その過程そのものを教材として残してきました。
やってみて見えてきたのは、agent-builder-kit の価値は単に plan を作ることではなく、人間と AI エージェントが同じ docs を見ながら、判断、実装、記録を分担できることにある、という点です。
一方で、これで完成ではありません。 並列実行、CI/CD、lint、より厳密な境界設計のように、project が大きくなるほど必要になるものはまだあります。 ただ、それらをあとから差し込めるようにしてあることも、この kit の強みです。
ここまで読んだあとに試すなら、まずは次の 3 つから始めるのが自然です。
- 自分の project に
agent-builder-kitを展開してみる - role や docs 構成を 1 つだけ自分用に拡張してみる
- ひとつの成果物を、実際に block / chunk / ticket で最後まで回してみる
この mdBook 自体も、そうやって作られました。
公開後は、この tutorial site と同じ repo に agent-builder-kit も置かれているので、本文を読みながらそのまま kit 側の資料を見に行けます。
もしここから先へ進むなら、次はあなた自身の project で、この flow がどこまで実運用に耐えるかを確かめてみてください。